
How to Login/sign in the Cox Webmail Account Anytime, Anywhere?
In today’s fast-paced world, staying connected is crucial, especially when it comes to managing your emails. With Cox webmail, you can access your account anytime, anywhere, ensuring that you never…

Level up Your CS:GO Stash Game with CSGoStash Pro Tips
CS:GO (Counter-Strike: Global Offensive) https://csgostash.com/ skins are virtual cosmetic items that can be applied to in-game weapons. These skins come in various rarity levels, ranging from common to extremely rare,…
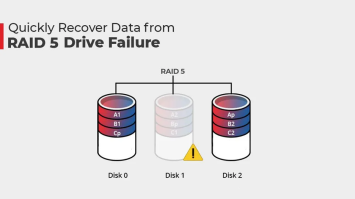
The Ultimate Guide to RAID 5 Recovery: How to Safeguard Your Data and Restore Lost Files
In today’s data-driven world, the security and recovery of our digital files are of utmost importance. For those utilizing RAID 5, a commonly used redundant array of independent disks, understanding…
VegaMovies: Stream and Download 4K , 2160p, 480p, 720p, 1080p & Free HD Movies
Welcome to VegaMovies, the ultimate destination for streaming and downloading the latest movies. With VegaMovies, you can enjoy a vast collection of free HD movies, right at your fingertips. Whether…

Effortless Access with Salesloft Login – Sign In Now
Welcome to Salesloft, the leading sales engagement platform that can revolutionize your sales process. With Salesloft login, you can effortlessly access your account and unlock a range of powerful tools…

Shop Quality Equipment at Northern Tool – Browse Now!
When it comes to finding top-quality northern tool and equipment for your projects, look no further than Northern Tool. As a trusted one-stop shop, Northern Tool offers a wide range…

Home Depot Credit Card: Login, Perks & Application Tips
The Home Depot Credit Card is perfect for customers who want to improve their home with ease and affordability. It gives you access to lots of perks and benefits. These…
Top 28 Hindilinks4u Alternatives to Watch Hindi Movies, TV Series, Documentaries
Ever wished you could watch the most recent films for free? Thus, HindiLinks4u is created! It resembles a magical package brimming with popular Bollywood films and TV programs. The greatest…

Medical Billing Companies: List Of Best 25 Medical Billing Companies
Medical Billing Companies: Medical claim collection is a laborious procedure. Fortunately, medical billing companies can assist healthcare professionals and businesses in streamlining the procedure. For your perusal, we have compiled…

20 Cybersecurity Statistics and Trends for 2022
No business in today’s technology-driven ecosystem has been immune to cybersecurity issues. Most businesses have data that is barely protected with an inferior cybersecurity setup and below-par IT security. It…